读书笔记:《疯狂java 程序员的基本修养》第三章——常见java集合的实现细节
1.java 中集合及其继承关系
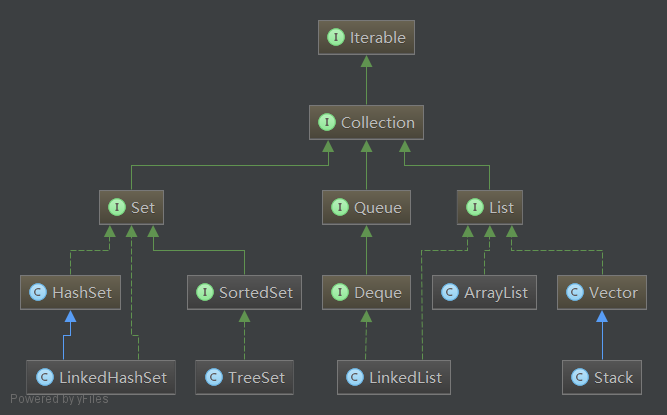
Map中常用的集合类类图如下:
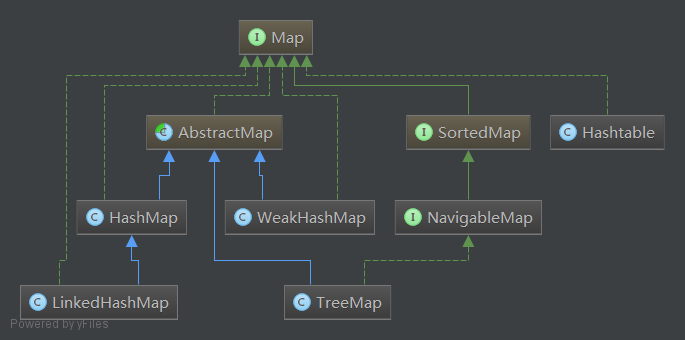
注:在jdk的安装目录下的 src.zip文件中就是jdk的源码,可以解压后查看。可通过NetBeans
等软件进行逆向工程查看类图。由于习惯使用idea,加上它对uml有一定的支持(主要是NetBeans新版不能在jdk1.8之后看类图),这里采用Idea生成类图。如下图:
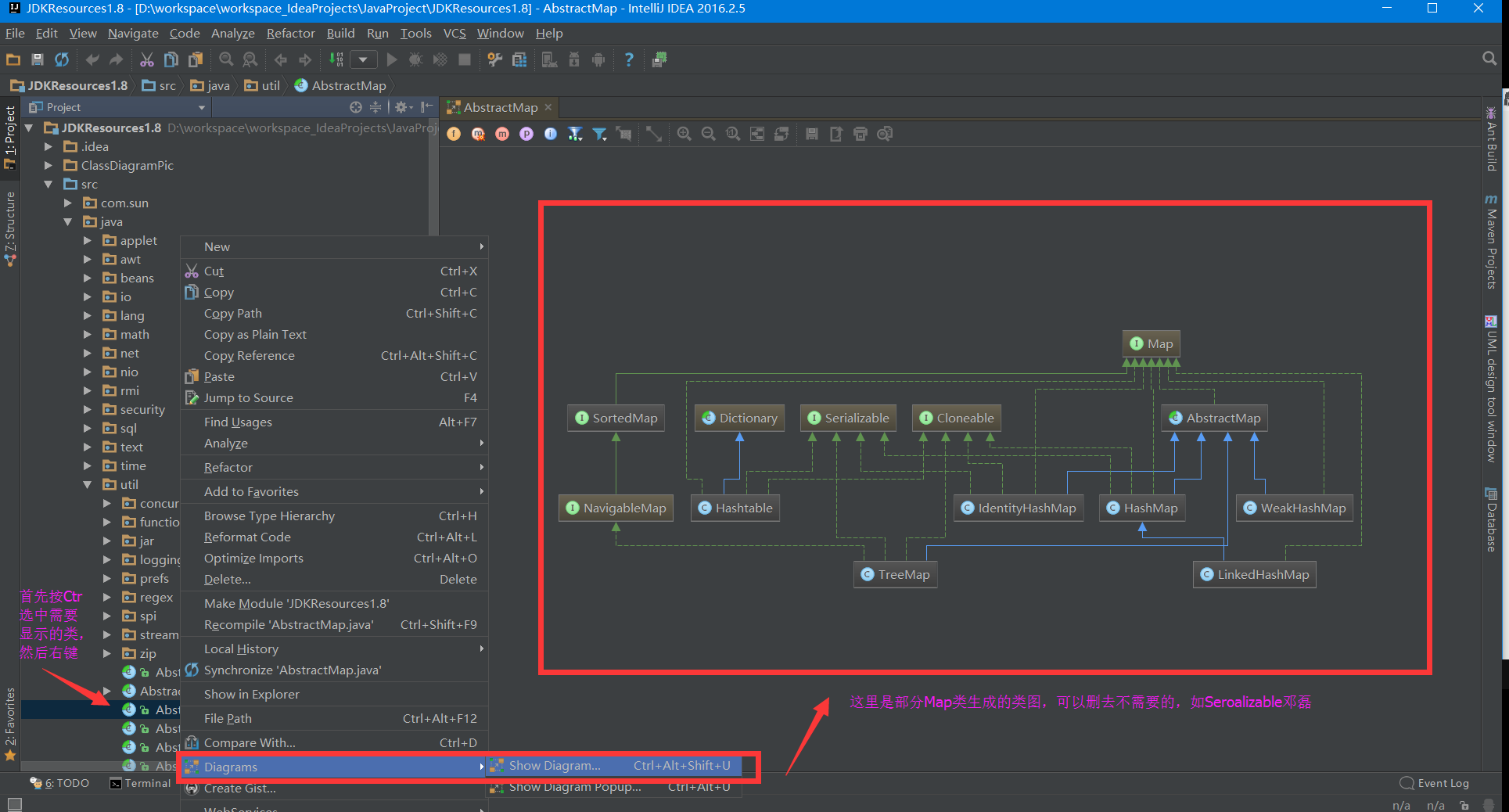
为了方便查看,可以新建工程,将jdk中的src解压放到该项目目录下,避免因为导入的包使有些类重复显示。
2. Set和Map
Set代表一种集合元素无序、不可重复的集合;Map代表一种由多个key-value对组成的集合。Map是Set集合的扩展。Map的所有的Key都是不可重复的,他们可以组成一个Set集合,对于Map而言,特可以看做是每个元素都是key-value对的集合。
HashSet和HashMap
HashSet:用采用Hash算法来决定集合元素的存储位置,可以保证快速存取集合;
HashMap:同样采用Hash算法决定key的存储位置,value紧随key存储。
在java中,虽然集合可以存储对象,但真正存储的是对象的引用,通过这些引用指向具体的对象,与引用类型的数组类似。
HashMap的构造器:
- HashMap()
构建初始容量为16,负载因子为0.75的HashMap; - HashMap(int initialCapacity)
指定初始容量(初始化时会找出大于initialCapacity的最小的2的N次方作为实际的容量,通常情况下实际的容量比initialCapacity大,除非指定的initialCapacity是2的n次方,则指定initialCapacity为2的N次方可以减小系统的开销) - HashMap(int initialCapacity, float loadFactor)
指定初始容量和负载因子
这里的负载因子,增大它会减小Hash表占用的空间,但会增加查询的时间开销;减小负载因子会提高数据查询性能,但会增加内存占用,可以根据实际的需要适当的设置它。
对于HashSet,大部分方法都是调用HashMap的方法来实现的,在hashset中元素实际上由HashMap的Kkey来保存,value则存的是一个PRESENT——一个静态的Object对象。
对于TreeMap,它底层采用的红黑树(一种自平衡二叉树了,树种的每个节点的值都大于或等于它左子树种所有节点的值,小于或等于它右子树种所有节点的值)来保存的,保证了所有的key都是从小到大排列的。
HashTable 是线程安全的。
3.Map和List
Map提供了get(K key)方法通过key获取value,List接口提供了get(int index)方法获取指定索引的值。
Stack是Vector的子类,是线程安全的,jdk1.6后不推荐使用它,可以使用ArrayQueue替换。
4.ArrayList和LinkedList
ArrayList和Vector的实现绝大部分都是相同的,只是Vector的方法使用了synchronized修饰,可以看做Vector是ArrayList的线程安全版本。
ArrayList是通过数组保存集合元素的,但在定义数组时用transient进行修饰,
ArrayList是一种顺序存储的线性表,LinkdList则是一种链式存储的线性表(双链表、队列、栈)。ArrayList在插入/删除数据时,需要将数据进行“整体搬家”。LinkedList是一个双链表,如果要获取某个元素必须进行逐个的搜索,但提供的有addFirst(E e)、addLast(E e)等方法,可以快速的定位需要的操作。
大部分情况下,ArrayList的性能总比LinkedList更优。对于经常需要添加和删除的,可以使用LinkedList.
5.Iterator迭代器
Iterator是一个迭代器接口,用于迭代各种Collection集合,这里使用了“迭代器模式”。
在迭代过程如果删除元素,若该元素不是最后一个,则会抛出异常。




